1. DeepLearning
Chapter 1. 딥러닝의 발전 5단계
1. 규칙기반 프로그래밍 (Rule - based Programming)
2. 전통머신러닝 기법 (Conventional ML)
★ 3. DeepLearning

★ 4. 사전학습과 미세 조정 (pre-training & fine tuning)

★ 5. 초거대모델과 제로샷/퓨샷
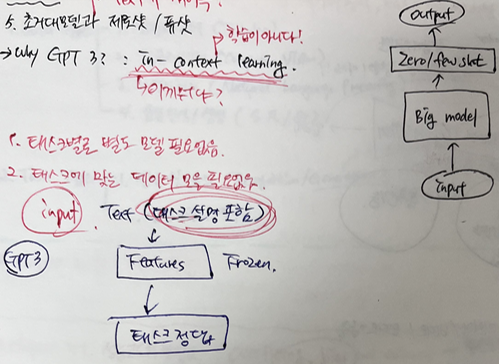
1.2 딥러닝 기술 종류들
1.2.1. 학습방식에 의한 구분
a. supervised
b. unsupervised
c. reinforcement
1.2.2. 데이터형식, 태스크 종류에 의한 구분
a. data type
b. task type
Chapter 2. 모델 학습법
Chapter 3. 성능고도화 방법
-. Overfitting, bias and variance
-. global / local minimum , 네트워크 안정화 (dropout, 정규화)
★정규화?!
1. 피쳐스케일링
2. 배치 정규화

왜 ? : 내부데이터분포변화(Internal Covariate Shift) , 모델 학습 과정에서 모델의 각 층에서 발생하는 파라미터 업데이트로 인해 다음 층의 활성화 값들의 분포가 변화하기 때문에 발생하는 것!
그러나 배치정규화를 수행하면 각 layer를 통과해도 데이터가 고르게 분포할 수 있음!
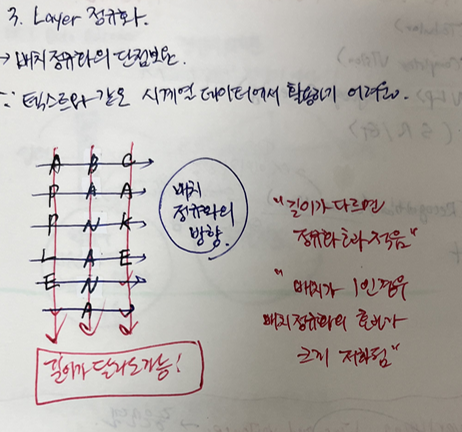
3. Layer 정규화
→ 배치정규화의 단점 보완; 텍스트와 같은 시계열 데이터에서 활용하기 어려움
4. 인스턴스 정규화 (ex. Image Style Transfer)
5. 그룹 정규화 (batch_size 작아도 잘 동작하게 해줌)
-. 가중치 초기화, 규제화, 학습론
ex. Xavier, He, ReLU 등..
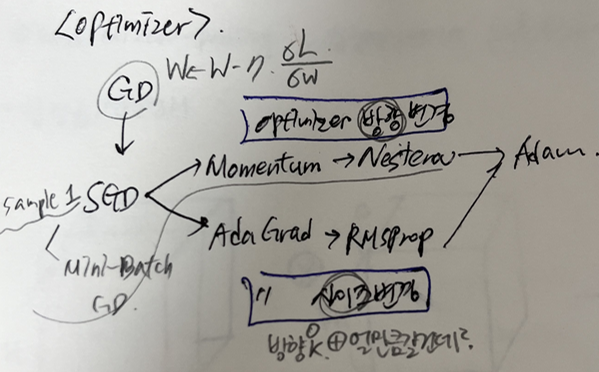
-. 다양한 최적화 알고리즘
-. 데이터 증강 및 그 외 방법
1. 데이터 증강 기법 : 충분한 양의 학습데이터 확보
- 데이터 증강이 모델 학습에 도움이되는가?
ex. 방향 예측인데 → 이미지만 회전하고 방향정보는 없음
ex. mnist dataset에서 6(six)을 rotation -> 9(nine) : 전혀다름!!
ex. pretrained LM을 이용한 방법
"오늘 날씨가" + temp 0.2 (좋다)
"오늘 날씨가" + temp 0.5 (상쾌해서 산책 다녀왔다)
"오늘 날씨가" + temp 0.8 (상쾌해서 하루종일 구름을 쫓아다녔다)
-. 모델이 고려할 수 있는 단어의 집합 크기나 확률분포 제한 (Top-p)
-. 모델이 고려할 수 있는 단어의 집합을 확률이 높은 상위 K개의 단어로 제한(Top-k)
2. 전이학습
- 의료데이터 같이 데이터를 많이 구하기 힘든 경우에 유용
3. 자기 지도 학습
- 대체작업학습, 대조학습, Autoencoder
2. Pytorch
-. PyTorch는 Python 기반의 오픈소스 머신러닝 라이브러리로, 최근 딥러닝 연구분야에서 가장 범용적으로 쓰이고 있음
-. 텐서 연산 및 자동 미분 기능을 제공하며, 딥러닝 모델을 쉽게 구축하고 학습할 수 있도록 도움
1. PyTorch의 주요 특징
-. 동적 연산 그래프 : 실행 시점에서 연산 그래프를 생성하여 직관적인 디버깅과 유연한 모델 설계 가능
-. Tensor 기반 연산 : numpy와 유사한 다차원 배열을 지원하고 GPU 가속 연산 가능
-. 자동미분(Autograd)
-. 신경망의 모듈화(torch.nn)
-. GPU 가속 지원 : .to('cuda')를 사용하여 GPU에서 연산 가능
2. PyTorch 기본 문법
2.1 텐서(Tensor) 생성
import torch
# 1D Tensor
x = torch.tensor([1.0, 2.0, 3.0])
print(x)
# 2D Tensor
y = torch.rand(2, 3) # 2x3 랜덤 텐서
print(y)
# GPU 사용 가능 여부 확인
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(f"Using device: {device}")
2.2 자동 미분(Autograd)
x = torch.randn(3, requires_grad=True) # 자동 미분 활성화
y = x * 2
z = y.mean()
z.backward() # z를 x에 대해 미분
print(x.grad) # x에 대한 미분값 출력
2.3 신경망 모델 구축
import torch.nn as nn
import torch.optim as optim
# 간단한 신경망 정의
class SimpleNN(nn.Module):
def __init__(self):
super(SimpleNN, self).__init__()
self.layer = nn.Linear(2, 1) # 입력 2차원, 출력 1차원
def forward(self, x):
return self.layer(x)
# 모델, 손실 함수 및 옵티마이저 설정
model = SimpleNN()
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)느낀점: 강의를 듣고 딥러닝의 발전 역사나 이론적인 부분은 어느정도 이해가 갔다. 하지만 본격적인 경진대회를 하면서 torch가 익숙해질 것 같다. 아마 익숙해지면 torch가 왜 널리 쓰이는 프레임워크인지 좀 더 알겠지?!
* dataloader로 받아오는게 처음에 가장 생소했다.
'Upstage AI Lab 6기' 카테고리의 다른 글
| 프로젝트를 위한 협업 : Github (1) | 2024.12.16 |
|---|---|
| 컴퓨터 공학 개론 (2) | 2024.12.11 |
| 프로젝트 수행을 위한 이론 1:Statistics (0) | 2024.12.02 |
| 프로젝트 수행을 위한 이론 2 : Python 모듈 학습 (0) | 2024.11.26 |
| Data Scientist 마인드셋 특강 학습블로그 (1) | 2024.11.19 |